
The Specification Problem Behind “Write Like Me”
I thought I was building a writing tool. I ended up building a specification system for taste, judgment, and self-knowledge.

In sports, people love to say the best athletes make the worst coaches.
What they do has been refined over so many years that it no longer feels like a learned skill. It feels like instinct. They can execute it, but they cannot always explain it. They cannot teach it because they have never had to turn it into language, even for themselves.
There is a particular kind of discomfort that comes from being on the wrong side of that gap. Not watching it from the stands, but running into it in your own work, trying to articulate something you’ve always done fluently, and finding out you don’t have the words.
I ran into it while building a tool to write in my voice.
The Smallest Useful Version
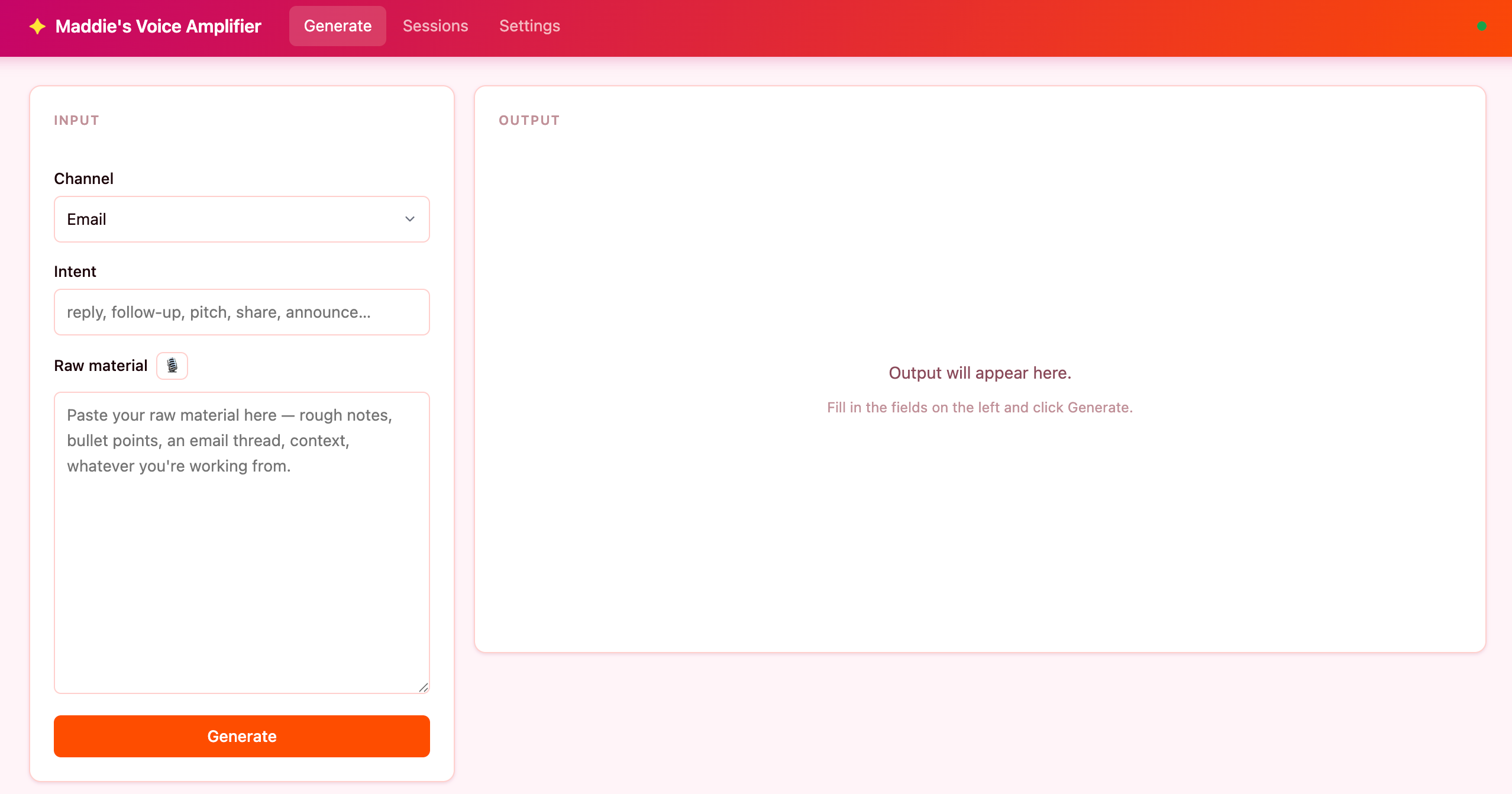
The premise was simple enough: a locally-hosted web app, no backend, no database, no login. You open it in a browser on your laptop, paste in raw material, choose the channel, and generate a draft. I built the smallest useful version, instrumented the learning loop, and let observed behavior drive the roadmap. That constraint was deliberate.
I have watched enough AI projects collapse under their own ambition to know the failure mode: full infrastructure, elegant architecture, all the features, never actually used. I did not want that. I wanted the smallest version that was genuinely useful and capable of teaching me something before I added anything else.
Before writing a line of code, I wrote a full PRD: user stories, data schema, feature requirements, priority levels, and a test plan.
Then I wrote a build guide, currently at v1.7, with exact system prompt templates, the diff analysis prompt verbatim, and a phase checklist so someone else could build their own version without starting from scratch.
The simplicity only worked because the thinking was rigorous. I could keep the scope tight because I had already decided what I was not building and why. That is the part that felt most like product management to me. Not the coding. The restraint.
Define the user. Narrow the use case. Decide what behavior matters. Build the smallest useful loop. Let the observed behavior tell you what deserves to exist next.
And the tool did teach me something. Just not what I expected.
What I Got Wrong First
The first version failed in a specific way. It was technically functional and structurally fine. But the drafts came back a little off. Close, but not quite me.
The voice guide I wrote in v1 was a polished document I wrote about myself from the outside. I declared my voice instead of discovering it. I invented rules I assumed I followed, or wanted to follow, rather than extracting patterns from writing I had actually done. Which is, unfortunately, very human.
The fix required me to go back and treat my own sent emails, posts, and drafts as source material. Run an extraction prompt on a real corpus. Derive the rules from what I found, not what I assumed I would find.
The v1.7 build guide has an entire section on this now, because it is the part most people would skip and the part that matters most.
It is tempting to start with aspiration.
“I want to sound thoughtful.”
“I want to sound sharp.”
“I want to sound warm but direct.”
“I want to sound like myself.”
Fine. But those are vibes, not instructions. The system needed evidence. That is where the real voice profile started.
But fixing the inputs exposed a second problem, and it was the more interesting one.
Voice Isn’t One Thing
Voice isn’t one thing. I knew this abstractly, but didn’t really get it until I was forced to write it like a product spec.
Email me starts direct, and warms over the course of the conversation. I match the energy of what I received. I don’t open with pleasantries unless something genuine warrants it. If there’s something personal in the context, I acknowledge it briefly before moving on. I make it easy to respond.
LinkedIn me opens with a unique observation and lets the observation do the work. No announcing the joke. No framing the insight before delivering it. Short paragraphs, and then stop.
Substack me builds. Starts in tension. Uses first person when it adds closeness. Ends without resolution, and names what’s unresolved and leaves it there.
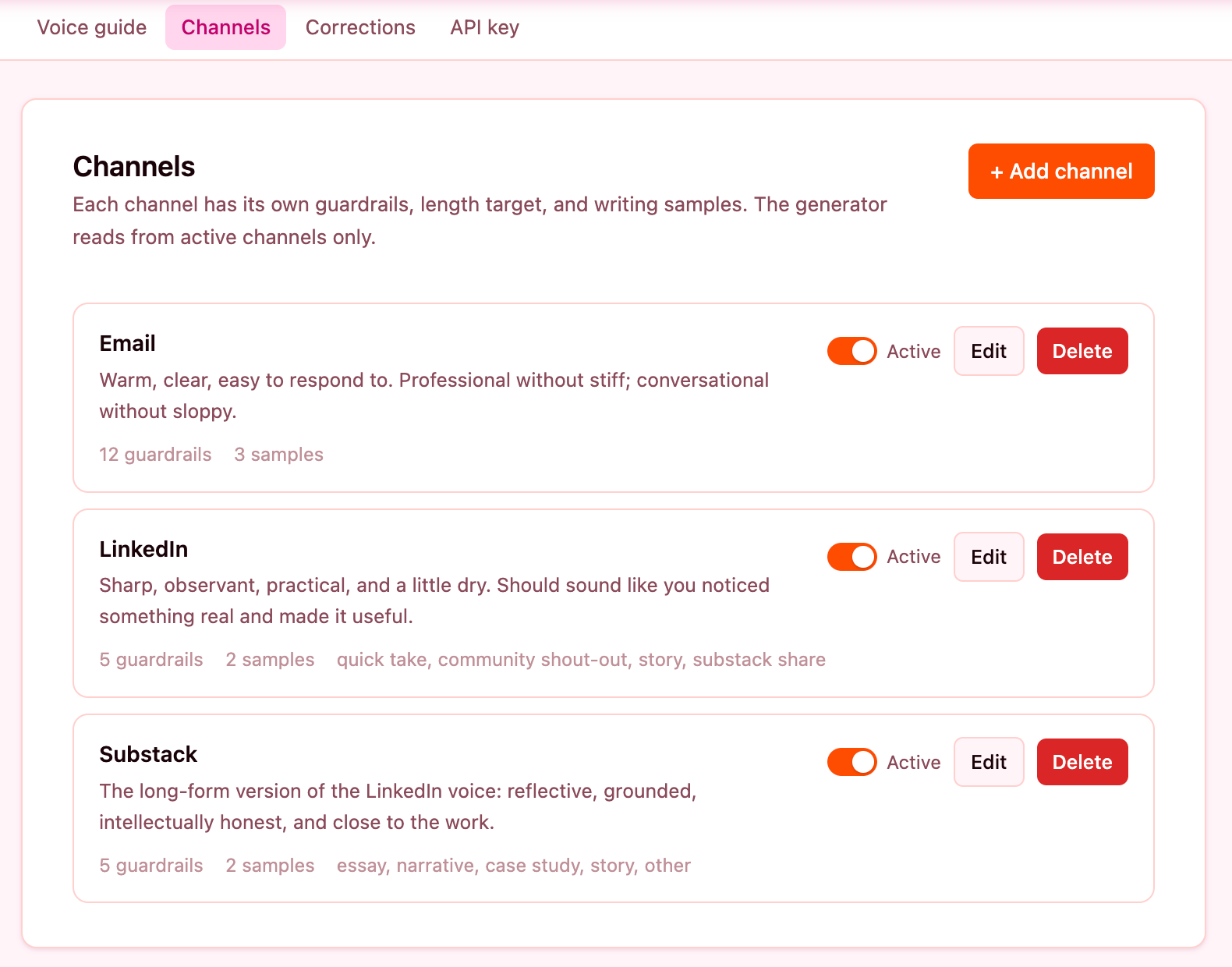
The same person can have multiple voices without being inconsistent. That is not fragmentation. It is context awareness.
We all do this. We write differently to a friend than we do to a stakeholder. We write differently in a third email in a thread than we do in a cold introduction. We write differently when we are trying to clarify, persuade, reassure, decline, challenge, or think out loud.
The Part That’s Like Hearing Your Own Voice on a Recording
You know the feeling. Someone plays back a video of you, and your first instinct is physical. Cue the self-critique: I hate my voice, why did I say that, do I really use my hands that much? You secretly hope and will that others hear something else. Except they don’t. That’s exactly how you sound. The gap between your internal sense of yourself and the external reality is just more visible than you’re used to.
Building the feedback loop in this tool is that feeling, in written form.
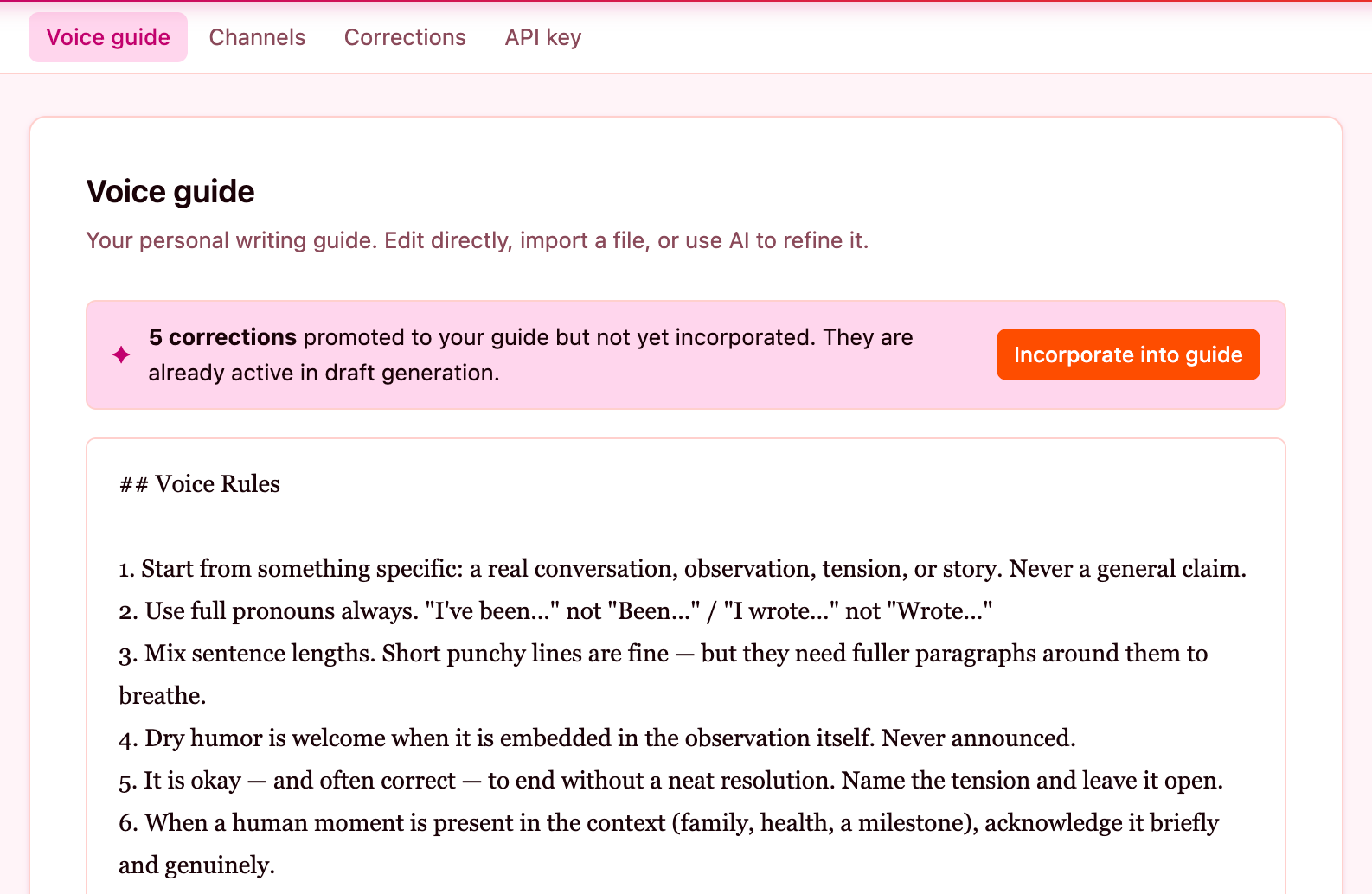
Every time I edited a draft before sending and pasted back what I actually sent, the system compared the two and inferred a rule from the gap. It generated a corrections log. Pending rules waiting for my review. Approve it and it gets folded into the voice profile. Dismiss it and it’s logged as a one-off.
Some of the inferences were straightforward. The AI kept reaching for polish I would not use, added length I would cut, closed with neat little resolutions I would never leave in. These were easy to approve.
Others were more uncomfortable.
A few surfaced patterns in how I handle certain kinds of conversations that I had not been looking at directly. Places where I soften too much. Places where I over-explain. Places where I avoid sounding too certain even when I am certain. The diff analysis does not know it is doing therapy. It is just comparing two documents.
The “never use” list was its own confrontation. Building it required acknowledging the phrases I was tempted by, which meant admitting I had habits I’d rather not have, not just preferences I was proud of.
The rule is the product
One of the clearest examples was how the system handled warmth in email. The AI would often add something like “I hope you’re doing well” which is not offensive or wrong, but also not me.
When I removed it enough times, the system inferred a rule: Do not add default warmth. Acknowledge something personal only when the source material gives you something specific to acknowledge. That rule is small, but it matters because it is the difference between generic politeness and actual attentiveness.
Another pattern showed up in reflective writing. The AI wanted to resolve things cleanly. It would end with a takeaway, a lesson, a tidy CTA. I kept undoing that.
The inferred rule became something like: Do not force resolution in reflective writing. If the tension is unresolved, name the tension and leave it open. Again, small rule. Big difference.
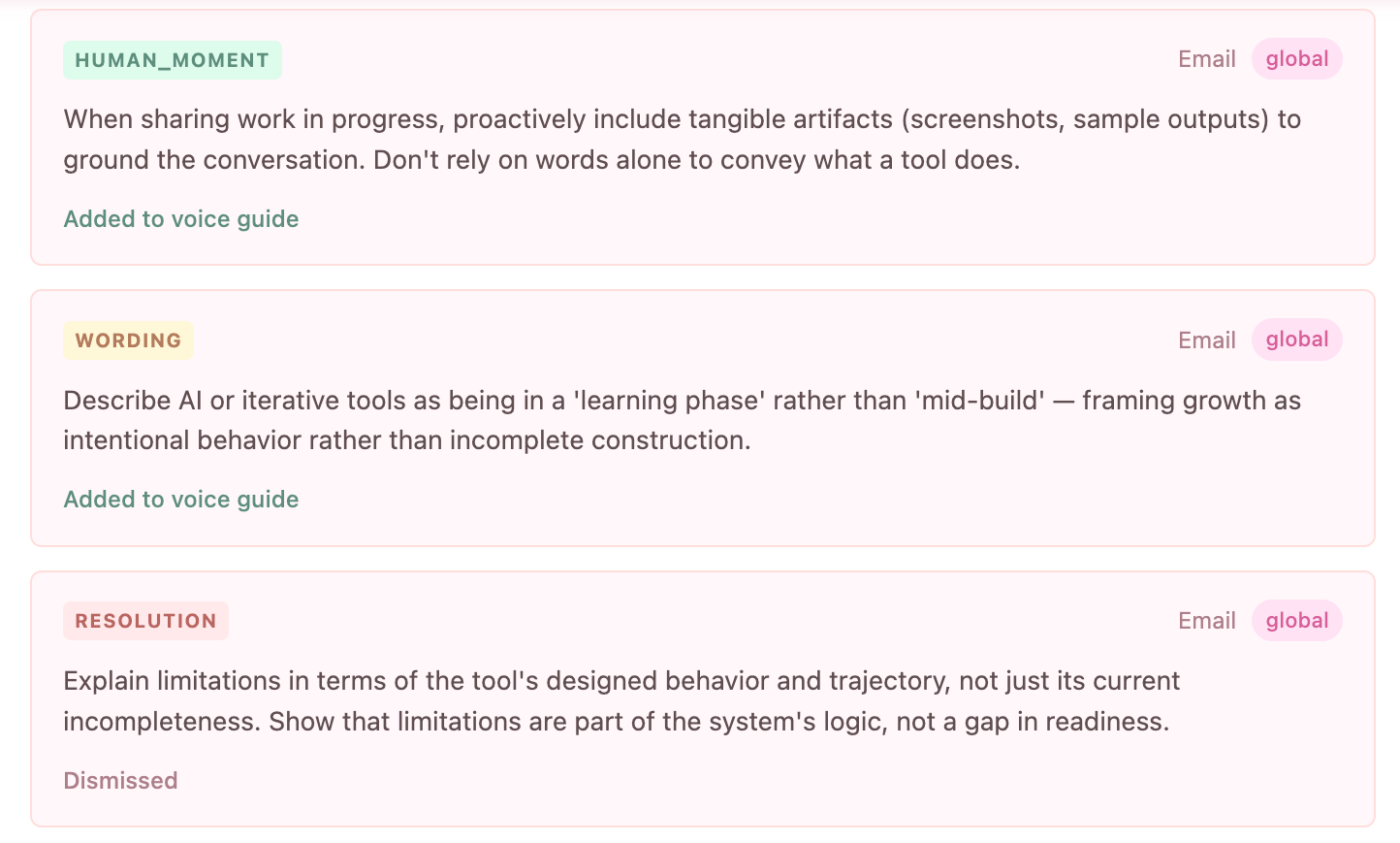
This is where the project started to get interesting to me. The product was not the generated draft. The product was the accumulation of better rules.
The draft is just where the rule gets tested.
Where This Shows Up Everywhere
This dynamic is not unique to voice tools. It shows up everywhere people try to translate instinct into instruction.
Explaining your decision process to a new hire and finding it full of exceptions you can’t justify. Writing a performance review and realizing the evidence doesn’t quite match the story you’ve been telling. Teaching something you’ve always done from muscle memory, and discovering mid-explanation that you don’t fully understand why it works. Building a personal knowledge system and having to articulate what “useful” actually means to you — not in theory, but consistently enough that a system can mirror it back.
The AI is a forcing function. It requires you to articulate things you’ve been getting by without naming. The articulation is where the self-knowledge actually happens.
What This Tells Me About AI Adoption
I’ve thought a lot about why AI adoption fails inside organizations. The answer I keep landing on is that it’s rarely technological. The tool works. The deployment fails because people haven’t done the work of definition. They say “be professional” and are disappointed by what comes back. They say “write like me” without having asked themselves what that means in any precise sense. Without that layer, AI produces something plausible.
The people who get the most out of AI are the ones who’ve had to be specific about what they want, and specific enough to be disappointed in a useful way. Not this doesn’t sound right, but this ended with a resolution when I needed to leave it open or this is too formal for a third email in a thread.
It develops from friction. It requires examples. It requires patience. Most people skip that part. Which is why so much AI adoption feels impressive in demos and flimsy in real work.
What I actually built
What I built is, at its core, a human specification document wearing the clothes of a product. A system prompt for myself. The act of writing it was clarifying not because the AI required clarity, but because I did.
The learning loop is accumulating real data now. The corrections log is showing me patterns in what I consistently change; the places where the AI defaults to polish I wouldn’t use, or length I wouldn’t take, or endings I’d never leave in.
The build guide is comprehensive, tool-agnostic, designed to be replicated by anyone who wants to run the same experiment on themselves. Swap in your own voice, run the extraction prompt on your own writing, and you have a version that sounds like you.
There’s more to build. A Supabase backend is on the roadmap. So is a Gmail integration and content-based triggers. I’ll add those when the data justifies it.
That restraint is, I think, the whole point. Build the smallest version that’s genuinely useful. Use it honestly. Learn what it reveals before deciding what comes next.
The build is never finished. Neither, apparently, is the self-knowledge.
I’m still testing the build guide, so I’m not treating it like a polished template yet. But if you’re building something similar and want to pressure-test it with me, subscribe/comment and I’ll share the working version.